实验准备#
Python 环境#
需要用到如下 Python 环境:
- PyTorch GPU 版本
- jupyter notebook
- tqdm
- matplotlib
- torchprofile
数据集准备#
Lab 1 中用到了 CIFAR-10 数据集,可以使用 https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz 直接下载,并将整个 cifar-10-batched-py 文件夹解压到 data/cifar10 文件夹内。
Part 1: Fine-grained Pruning#
Question 1#
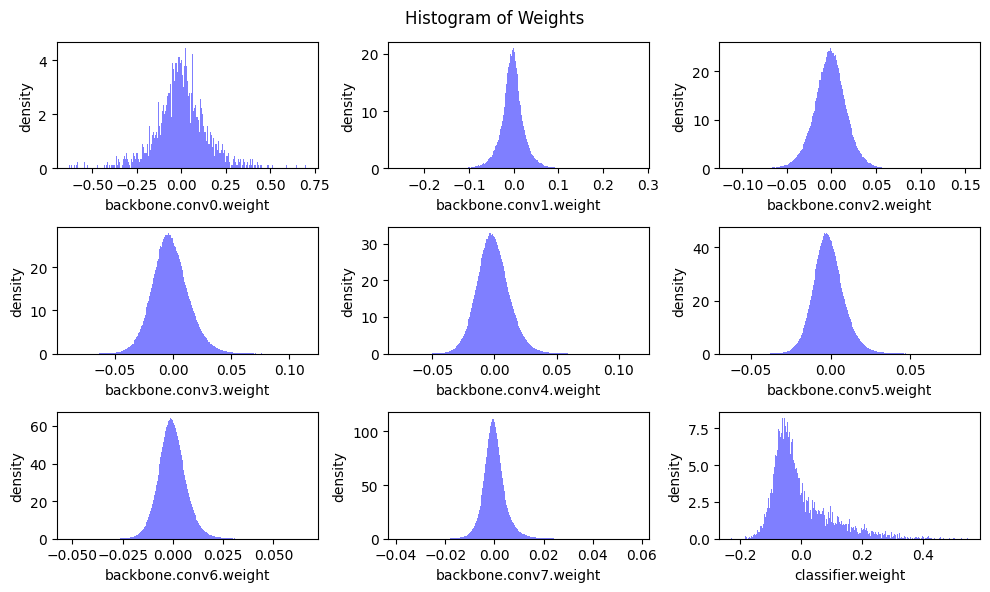
除最后一层分类头外,其它层均服从均值为 0 的无偏正态分布,这意味着占很大比例的参数是可以被移除的,这为模型压缩留下了很大的空间。
Question 2#
第二个问题要求实现细粒度剪枝,即可以对权重矩阵中的单个元素进行剪枝,关于不同颗粒度的剪枝介绍,见 课程第三讲笔记。
这里使用每个参数的绝对值来表示其重要性,剪掉不重要的参数,保留重要的参数。
本问比较简单,根据稀疏度计算出需要剪去的参数总量,然后使用找到阈值并根据阈值得到 mask 矩阵。唯一的一个注意点是计算 mask 矩阵是使用大于而不是大于等于,这是由于计算得到的阈值也需要被剪掉。
1
2
3
4
5
6
7
8
9
10
|
##################### YOUR CODE STARTS HERE #####################
# Step 1: calculate the #zeros (please use round())
num_zeros = round(sparsity * num_elements)
# Step 2: calculate the importance of weight
importance = tensor.abs()
# Step 3: calculate the pruning threshold
threshold = torch.kthvalue(importance.view(-1), num_zeros).values
# Step 4: get binary mask (1 for nonzeros, 0 for zeros)
mask = importance > threshold
##################### YOUR CODE ENDS HERE #######################
|
Question 3#
问题三要求我们在一个 5 x 5 的矩阵中保留 10 个元素,相应的稀疏度为 $1-\frac{10}{25}$,此问就算结束了。
Question 4#
此问对 VGG 网络每一层进行了灵敏度分析,建议将步长修改为 0.2 或者 0.1,以获得更加平滑的灵敏度曲线。
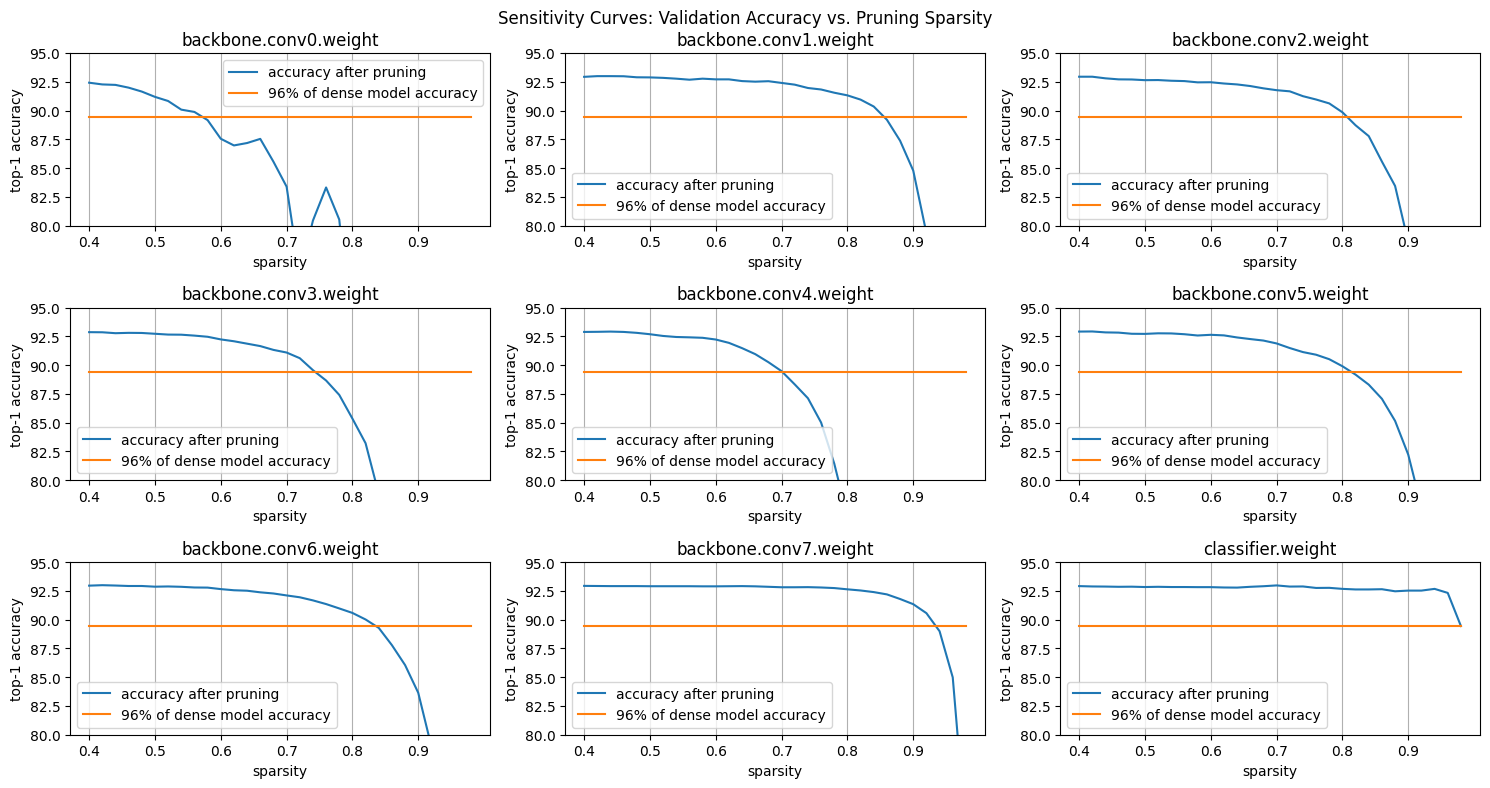
从图中可以看到大部分层中,随着稀疏度的增加,模型精度相应变低,不同层的敏感程度不同,第 0 个卷积层对稀疏度最敏感。
Question 5#
第 5 问中,要求根据前面灵敏度分析结果和模型参数计算量,设置每一层剪枝时的稀疏度。❗️注意,最终整个模型的稀疏度很大程度上取决于参数量比较大的层的稀疏度,对于参数量比较大的层,可以考虑设置比较高的稀疏度。
我选择的稀疏度参数为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
sparsity_dict = {
##################### YOUR CODE STARTS HERE #####################
# please modify the sparsity value of each layer
# please DO NOT modify the key of sparsity_dict
'backbone.conv0.weight': 0,
'backbone.conv1.weight': 0.6,
'backbone.conv2.weight': 0.5,
'backbone.conv3.weight': 0.5,
'backbone.conv4.weight': 0.5,
'backbone.conv5.weight': 0.6,
'backbone.conv6.weight': 0.6,
'backbone.conv7.weight': 0.75,
'classifier.weight': 0
##################### YOUR CODE ENDS HERE #######################
}
|
经过剪枝后,大小约为原始稠密模型的 38.48%,精度从 92.9% 降低到了 91.50%,在 5 轮的微调后,模型精度恢复为 92.95%。
Part 2: Channel Pruning#
Question 6#
第 6 问需要实现 Channel Pruning,剪枝标准是只保留前 k 个通道。问题本身时简单的,用好 Python 中的切片即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
def get_num_channels_to_keep(channels: int, prune_ratio: float) -> int:
"""A function to calculate the number of layers to PRESERVE after pruning
Note that preserve_rate = 1. - prune_ratio
"""
##################### YOUR CODE STARTS HERE #####################
return int(round(channels * (1 - prune_ratio)))
##################### YOUR CODE ENDS HERE #####################
@torch.no_grad()
def channel_prune(model: nn.Module,
prune_ratio: Union[List, float]) -> nn.Module:
"""Apply channel pruning to each of the conv layer in the backbone
Note that for prune_ratio, we can either provide a floating-point number,
indicating that we use a uniform pruning rate for all layers, or a list of
numbers to indicate per-layer pruning rate.
"""
# sanity check of provided prune_ratio
assert isinstance(prune_ratio, (float, list))
n_conv = len([m for m in model.backbone if isinstance(m, nn.Conv2d)])
# note that for the ratios, it affects the previous conv output and next
# conv input, i.e., conv0 - ratio0 - conv1 - ratio1-...
if isinstance(prune_ratio, list):
assert len(prune_ratio) == n_conv - 1
else: # convert float to list
prune_ratio = [prune_ratio] * (n_conv - 1)
# we prune the convs in the backbone with a uniform ratio
model = copy.deepcopy(model) # prevent overwrite
# we only apply pruning to the backbone features
all_convs = [m for m in model.backbone if isinstance(m, nn.Conv2d)]
all_bns = [m for m in model.backbone if isinstance(m, nn.BatchNorm2d)]
# apply pruning. we naively keep the first k channels
assert len(all_convs) == len(all_bns)
for i_ratio, p_ratio in enumerate(prune_ratio):
prev_conv = all_convs[i_ratio]
prev_bn = all_bns[i_ratio]
next_conv = all_convs[i_ratio + 1]
original_channels = prev_conv.out_channels # same as next_conv.in_channels
n_keep = get_num_channels_to_keep(original_channels, p_ratio)
# prune the output of the previous conv and bn
prev_conv.weight.set_(prev_conv.weight.detach()[:n_keep])
prev_bn.weight.set_(prev_bn.weight.detach()[:n_keep])
prev_bn.bias.set_(prev_bn.bias.detach()[:n_keep])
prev_bn.running_mean.set_(prev_bn.running_mean.detach()[:n_keep])
prev_bn.running_var.set_(prev_bn.running_var.detach()[:n_keep])
# prune the input of the next conv (hint: just one line of code)
##################### YOUR CODE STARTS HERE #####################
next_conv.weight.set_(next_conv.weight.detach()[:, :n_keep])
##################### YOUR CODE ENDS HERE #####################
return model
|
记得一提的是框架已经给出的代码,所谓 Channel 是在卷积中才会出现的,剪枝也是对输出通道进行剪枝。例如,当前卷积核中本来有 k 个通道输出,剪枝后变成 l 个输出通道,那么下一层的卷积核的输入通道也要相对应地从 k 变成 l。此外一般 Conv 后都会有一个 Batch Norm,应该这个 Conv 的 weight、bias、running_mean 和 running_var 也要一起进行剪枝。
Question 7#
改进 Channel Pruning,使用 Frobenius 范数来评估每一个通道的重要程度。本问的核心就是 Frobenius 范数的计算,说明中推荐使用 torch.norm 进行实现,但是官网文档中提到这个 API 已经被弃用,这里改用 torch.linalg.vector_norm()。根据文档,dim 指定为需要展开为向量的维度,即第 [0, 2, 3]。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
# function to sort the channels from important to non-important
def get_input_channel_importance(weight):
in_channels = weight.shape[1]
# importances = []
# # compute the importance for each input channel
# for i_c in range(weight.shape[1]):
# channel_weight = weight.detach()[:, i_c]
# ##################### YOUR CODE STARTS HERE #####################
# importance = torch.linalg.norm(channel_weight, ord="fro", dim
# ##################### YOUR CODE ENDS HERE #####################
# importances.append(importance.view(1))
# return torch.cat(importances)
return torch.linalg.vector_norm(weight, ord=2, dim=(0, 2, 3))
@torch.no_grad()
def apply_channel_sorting(model):
model = copy.deepcopy(model) # do not modify the original model
# fetch all the conv and bn layers from the backbone
all_convs = [m for m in model.backbone if isinstance(m, nn.Conv2d)]
all_bns = [m for m in model.backbone if isinstance(m, nn.BatchNorm2d)]
# iterate through conv layers
for i_conv in range(len(all_convs) - 1):
# each channel sorting index, we need to apply it to:
# - the output dimension of the previous conv
# - the previous BN layer
# - the input dimension of the next conv (we compute importance here)
prev_conv = all_convs[i_conv]
prev_bn = all_bns[i_conv]
next_conv = all_convs[i_conv + 1]
# note that we always compute the importance according to input channels
importance = get_input_channel_importance(next_conv.weight)
# sorting from large to small
sort_idx = torch.argsort(importance, descending=True)
# apply to previous conv and its following bn
prev_conv.weight.copy_(torch.index_select(
prev_conv.weight.detach(), 0, sort_idx))
for tensor_name in ['weight', 'bias', 'running_mean', 'running_var']:
tensor_to_apply = getattr(prev_bn, tensor_name)
tensor_to_apply.copy_(
torch.index_select(tensor_to_apply.detach(), 0, sort_idx)
)
# apply to the next conv input (hint: one line of code)
##################### YOUR CODE STARTS HERE #####################
next_conv.weight.copy_(torch.index_select(next_conv.weight.detach(), 1, sort_idx))
##################### YOUR CODE ENDS HERE #####################
return model
|
相比没有计算重要性的通道剪枝,改进剪枝后的模型的准确率从 28.15% 提升到 36.81。经过微调后恢复为 92.41%。
Question 8#
- 为什么剪枝 30% 但是计算量减少了大约 50%。
VGG 模型主要由卷积层构成,卷积层的计算量 FLOPs 为:
$$
FLOPs = K\times K\times C_{in}\times C_{out}\times H \times W
$$
其中输入和输出通道都变为原来的 70%,因而总计算量变为原来的 49%。
- 解释一下为什么延迟(latency)的减少比例略小于计算量的减少比例。
延迟不仅仅来源于计算,还来自于数据的搬运,这部分时间在没做算子融合的情况下减少并不显著。
Question 9#
-
讨论一下 fine-grained pruning 和 channel pruning 的优缺点。
细粒度剪枝:压缩率更高、对硬件不友好、延迟高;
通道剪枝:压缩率低、硬件友好、延迟低、易于微调。
-
如果想在智能手机上加速模型,使用哪种方案更合适。
通道剪枝。智能手机上一般缺乏对于稀疏矩阵的支持,选取对硬件更友好的方案。
第一个 Lab 本身比较简单,做完能够建立起对于剪枝的初步认识,希望后面的实验能够上点强度,代码量也太少了😂。