MIT 6.824 Distributed Systems 第三讲学习笔记,简单介绍了存储系统和一致性,主要介绍了 GFS 中的文件读写流程。
存储系统概述
存储系统在分布式系统中相当重要:如果能够建立一个可靠的存储系统,可以讲其它应用构建为无状态的,而在存储系统中持久存储状态,这能够大量简化应用设计。这种情况下,应用即使崩溃也可以迅速重启,并从存储系统中读取状态进行恢复。
这也意味着,存储系统本身必须具备良好的容错能力,存储系统自身设计相当困难:
- 高性能:需要跨服务器共享数据
- 多服务器:这意味着某个服务器挂掉是常态
- 容错设计:必须有 replication 冗余备份
- 冗余备份:可能导致潜在的不一致性
- 强一致性:需要一致性协议和网络通信,进而降低性能
Ideal consistensy
理想的一致性系统应该表现得像一个单机系统。
在一致性系统中,涉及到并发问题。在分布式系统会出现一些额外的并发问题。例如,当 A 和 B 依次分别发送像 X 写入 1 和 2 的请求,C 和 D 再依次发送读取 X 的请求。CD 读到的数据组合可能为 (1, 1)、(1, 2)、(2, 2),而不可能出现 (2, 1)。
而在分布式系统中,同样是上述读写次序,A 的写入请求可能只背服务器 S1 接收到、B 的写入请求只被 S2 接受接受到,而 C 的读取请求被 S2 处理,D 的读取请求被 S1 处理,那么 CD 读到的数据组合为 (2, 1)。这里我们需要一种同步协议来协调读者和写者。本课程的后半段将花费大量篇幅介绍不同的同步协议,他们基本都是在容错和一致性之间的折中。
GFS: Google File System
GFS 是本课程第一个案例分析,其是一个以高性能作为设计目标的分布式文件系统,其具备副本、容错、一致性。
特点
这篇论文发表于 21 世纪初,彼时学界对于分布式系统已经有较为成熟的理论体系,但缺少实际可用的工业界产品。GFS 作为一个成功的分布式文件系统,其实际上并非是一个标准的学术界研究的分布式系统:
- 单一 master
- 可能存在不一致性
GFS 的特点:
- Big:具有大的数据集
- Fast:自动将文件分片到多个服务器上
- global:所有应用都能看到相同的文件
- fault tolerance:自动容错和恢复机制
整体设计
GFS 架构图如下所示:
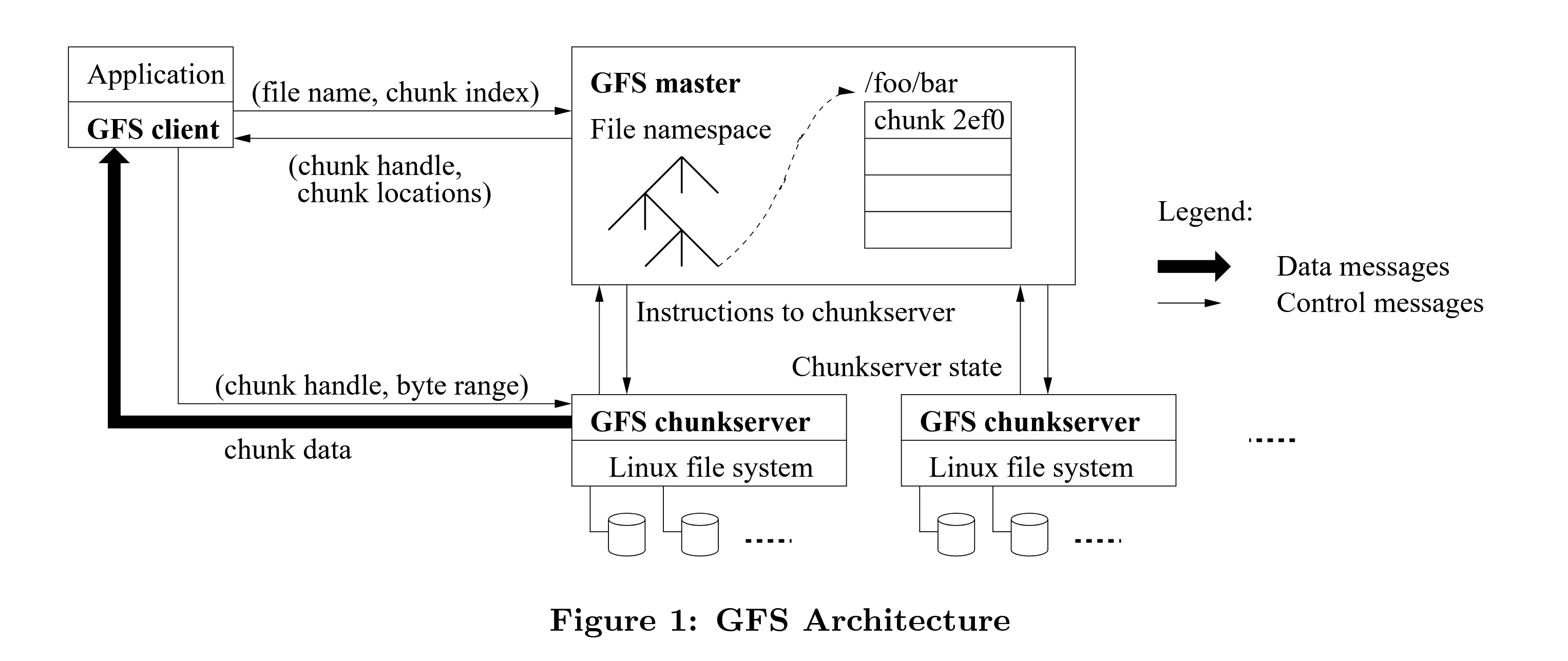
每个文件被分为多个 chunk,每个 chunk 不是很小,约为 64MB。应用告知 master 需要访问的文件名和 chunk 好,master 返回对应的句柄和存储位置,应用再根据存储位置找到对应的 chunk server,发送访存请求。
Master
Master 维护一组从文件名到 chunk 句柄数组的映射表。对于每一个 chunk 句柄,Master 维护其版本号、持有该句柄的服务器列表、这些服务器的主从次序、服务器的租约长度(lease time)信息。此外,Master 还要负责日志和检查点保存。Master 在响应请求之前,首先将其写入日志,这意味着即便 Master 挂了,也可以从日志中恢复重建,并响应请求。
文件名到 chunk 句柄数组的映射表应当作为持久状态被 Master 定期保存到磁盘上,而与 chunk 相关的服务器信息则不必要,该信息可以在 Master 重启时主动要求其它服务器汇报其持有的 chunk 信息从而重建。chunk 版本号也需要作为持久状态,因为 Master 需要明确了解整个系统每个句柄的最新版本号,而不是由其它服务器汇报,以应对那些真正持有最新版本号的服务器也许也一起挂掉的情况。
读写流程
- 读文件流程
- 客户端将文件名和偏移量发送给 Master。
- Master 告知客户端句柄、持有该句柄的服务器列表、版本号。
- 客户端缓存上述信息。这一步可以减少 Master 的压力、网络流量和客户端自身访问文件的延迟。
- 客户端按照由近及远的顺序依次尝试从服务器列表中获取文件。
- chunk 服务器检查版本号,通过则将文件数据发送给客户端。
- 写入流程之 append 操作
- 客户端告知 Master 文件名。
- Master 根据文件名找到对应 chunk 句柄。Master 根据 chunk 句柄找到持有该句柄的 chunk 服务器列表。 如果没有主 chunk 服务器,Master 选择一个作为主 chunk 服务器,该主 chunk 服务器被授权一段时间的 lease 即租约,时间内其可以对该句柄进行修改。同时 Master 增加版本号,该版本号信息将分发给所有持有该句柄的服务器,句柄服务器应当将版本号持久保存在磁盘上。
- Master 告知客户端文件主从 chunk 服务器列表和版本号。
- 客户端将文件由近及远尝试发送给 chunk 服务器。
- 如果是从 chunk 服务器接收到了写入内容,其再转发给主 chunk 服务器,主服务器转发给从服务器。如果一切正常,写入完毕后主服务器告知客户端成功写入。如果错误,则告知客户端错误原因。
- 如果客户端接受到错误信息。其会自动重试,直至成功。以确保 at-least-once RPC 语义。
- 在第二次重试中,主 chunk 服务器将不会在原有磁盘 offset 上写入,该位置已经存放了第一次写入的内容,其会向后寻找新位置。因此,磁盘上可能存有重复的记录。