本文为Programming Massively Parallel Processors A Hands-on Approach 4th Edition(中文名:大规模并行处理器编程实战)第一部分学习笔记,包括全书前六章。
全书第一部分主要内容有:CUDA 架构、CUDA C 编程入门、CUDA 优化技术简介。
Chapter 1: Introduction 简介
应用程序需求的算力和 CPU 能够提供的算力一直是一对相互促进的矛盾。上世纪八九十年代,通过不断提高单核频率和每个时钟周期执行的活动数让算力达到了 TFLOPS 的级别。然而,到了 21 实际,由于功率和散热限制,难以通过提升频率进一步提高算力。这种情况下,多核 CPU 就应运而生了。多核 CPU 可以同时执行多个指令序列,因此应用程序也必须将任务分为多个部分以便在多个核心上同时执行。如果不针对多核进行优化,那程序很难享受到多核带来的算力提升。
这类能够享受到多核性能提升的程序被称为并行程序 parallel programs。
1.1 Heterogeneous parallel computing 异构并行计算
2003 年,在处理的进化道路上出现了一个分岔口。
一种以多核 multicore 见长,每个核心都是完整的一个单核 CPU,这就是现代的多核 CPU。例如 Intel 发布的最新处理器中,往往具有十几个核心,每个核心都具有超线程能力,并且完整实现了 x86 指令集。
另一种以多线程 many-thread 见长,能够同时执行非常非常多的线程,往往具有极强的浮点计算能力,这就是现代 GPU。例如 NVDIA 发布的 A100 GPU 中,其双精度浮点算力达到 9.7 TFLOPS,同期的 Intel 24 核处理器只有 0.66 TFLOPS。
如下图所示,这一差异源自二者设计理念的差别。CPU 为了支持顺序执行指令序列,其在设计时最小化了算数运算的延迟,并且提供了很大的末级缓存以便快速存取大量数据,还应用了许多复杂分支预测和执行控制逻辑技术来减少分支指令带来的延迟。上述技术消耗了大量的芯片面积和功耗,这种设计理念被称为面向延迟的设计。与之相反的是 GPU 的设计理念,即面向吞吐量的设计。GPU 的快速发展起初是由电子游戏推动的,每个游戏帧的渲染都需要计算大量浮点数,因此 GPU 最大化了浮点数的计算单元。
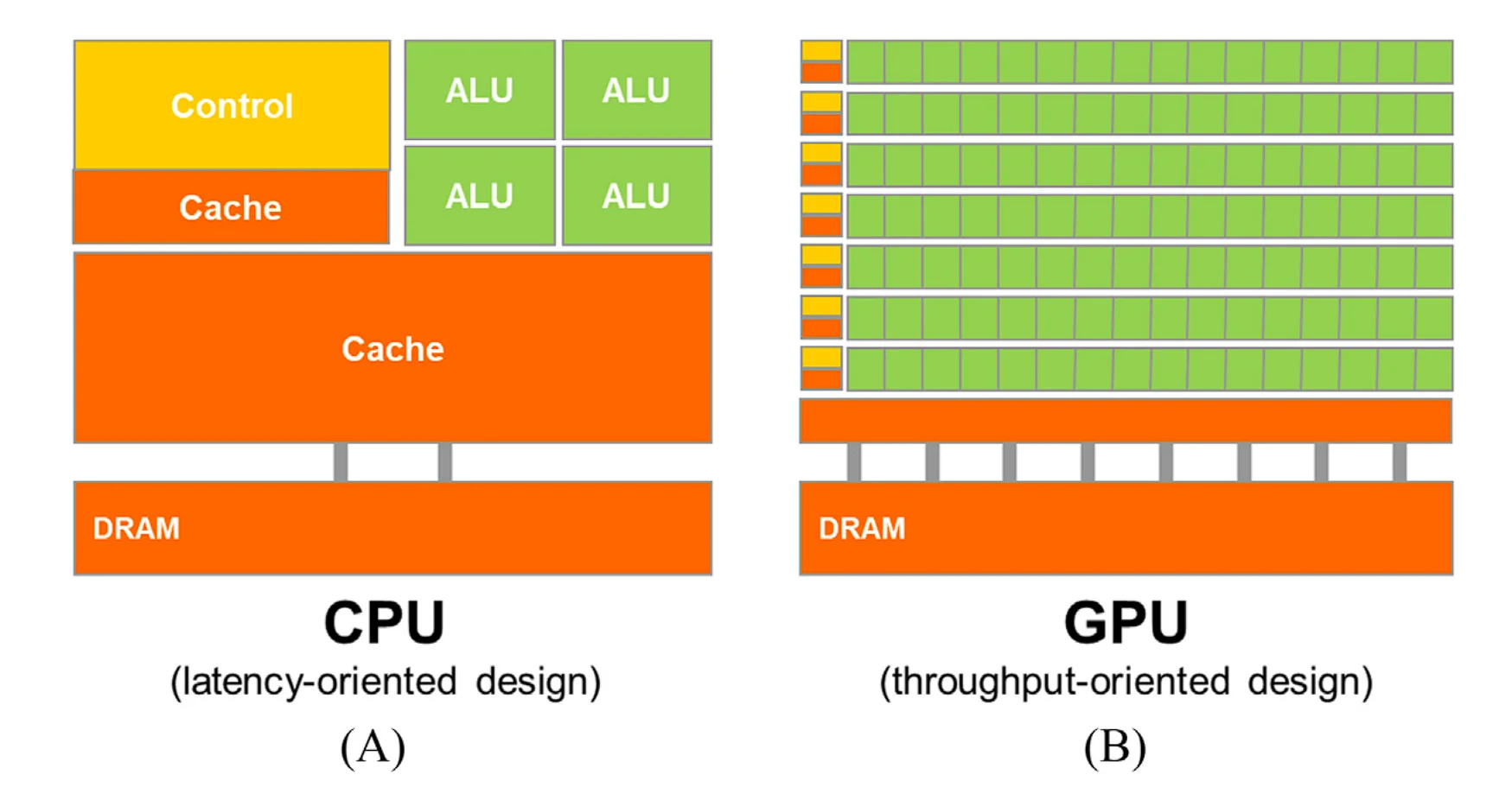
对于 GPU 而言,同时进行大量的浮点计算是重要的,但是同时大量访存这一点也很重要。GPU 要能够在内存中快速移动大量数据。GPU 通常可以接受宽松内存模型 1。
丧心病狂的芯片研发人员为了榨取更多的性能,在 PSO 模型基础上,更进一步的放宽了内存一致性模型,不仅允许 store-load,store-store 乱序。还进一步允许 load-load,load-store 乱序, 只要是地址无关的指令,在读写访问的时候都可以打乱所有 load/store 的顺序,这就是宽松内存模型(RMO)。
然而,作为通用处理器的 CPU 为了满足各类应用程序、老旧 OS、IO 设备等的要求,在内存上就不能这么激进了。通常,GPU 的内存带宽能够达到 CPU 的 10 倍。
通常来说,提高减少延迟比提高吞吐量要困难,通过让计算单元翻倍就能让吞吐量翻倍。GPU 为了提高吞吐量,增大了算术元件和内存的延迟。
GPU 应用程序需要有大量的并行线程,当在等待内存数据时,GPU 的其它线程可以用于查找接下来要完成的任务。这类设计模式被称为面向吞吐量设计。
GPU 执行吞吐量很高,然而其并不擅长 CPU 所擅长的领域,因此,在英伟达 2007 年引入的 CUDA 模型中,其支持 CPU-GPU 联合执行。
在 CUDA 出现之前,与 GPU 交互的接口为 OpenGL 和 Direct 3D,它们都是用于绘制像素的 API,即便是用 GPU 来计算,其底层仍是这些与像素相关的接口。这种技术被称为 GPGPU,general purpose GPU。
在 CUDA 推出以后,GPU 计算不再需要调用图形接口,而是由专用的通用计算接口。
1.2 Why more speed or parallelism 为什么要并行化?
现在普通应用已经运行得足够快了,为什么还要并行化?事实上,在很多任务中,运行速度仍是瓶颈。得益于 GPU 的迅速发展,科学计算、视频、电子游戏、深度学习等也繁荣起来。
以上种种应用都有一个特点,就是有大量的数据需要处理。这种情况下,可以并行执行大数据处理任务,以显著提升执行效率。
1.3 Speeding up real applications 加速实际应用
如何评价并行化后的加速倍率?我们通过比较加速前后的运行时间即可,通过加速将运行时间从 200 秒减少到 10 秒,那我们就称加速倍率为 20×。
一个应用程序的加速倍率,取决于该程序能够并行化的部分的比例。例如,如果一个程序有 30% 的部分可以实现 100×加速,那么这个程序的执行时间最多只能降低 29.7%,整体加速效果为 1.42×。一个系统的加速效果严重受制于可加速的部分的比例,这一定律被称为阿姆达尔定律。
另一个制约加速倍率的因素是内存带宽,因此在并行技术中一个重要方面就是尽可能减少主机内存访存次数,改为访问 GPU 显存。
1.4 Challenges in parallel programming 并行编程中的挑战
编写并行程序可能很难,有些并行程序需要完成的任务可能有很多,甚至比原始版本跑得还慢。主要困难有以下几个方面。
- 编写并行算法的思维方式和惯用的顺序执行的算法思维方式完全不同。
- 并行算法很容易受到内存贷款瓶颈。
- 并行化的算法对于输入数据的特征更加敏感。
- 并行化的算法不同线程之间可能需要协作,而这些线程之前的同步也会带来额外开销。
1.5 Related parallel programming interfaces 相关并行编程接口
在过去几十年中,有不少并行编程语言和模型被提出。对于共享内存的多处理器系统,最常用的是 OpenMP,对于可扩展集群计算,最常用的是 Message Passing Interface (MPI)。
OpenMP 由编译器和运行时两部分组成。程序员通过在代码中指定指令 directives 和编译指示 pragmas,编译器可以生成并行代码,运行时负责通过管理线程和资源以支持并行运行。OpenMP 通过提供自动编译和运行时支持使得程序员们不需要考虑并行编程的细节,也方便在不同的系统/架构中迁移
在 MPI 中,同一个簇内的计算节点不共享内存,所有的数据和信息通过消息传递机制进行,MPI 适合超大规模的 HPC 集群(节点超过 10 万个)。由于不共享内存,对于输入输出的分割工作,大部分由编程人员来完成。与之相反,CUDA 提供了共享内存。
2009 年,工业界几个巨头,包括苹果、因特尔、AMD 和英伟达一起开发了一个标准编程模型 OpenCL。
1.6 Overarching goals 首要目标
最首要的目标是实现在大规模并行编程中的高性能编程。本书会涉及一些对硬件架构的直觉上的理解,一些计算思维,即以适合大规模并行处理器的执行方式来思考问题。
第二个目标是在并行编程中实现正确的功能和可靠性。CUDA 提供了一系列工具来对代码的功能和性能瓶颈进行 Debug。
第三个目标是实现对未来更高性能的硬件的可扩展性。这种可扩展性是通过规范化和本地化内存,以减少在更新数据结构中对关键资源的读写和冲突来实现的。
1.7 Organization of the book 本书的架构
略。
Chapter 2: Heterogeneous data parallel computing 异构数据并行计算
2.1 Data parallelism 数据并行化
数据彼此独立是数据并行化的基础,通过对计算任务的重新组织,可以将数据并行化,进而获得可观的加速效果。以将像素灰度化举个例子,通过如下公式来计算灰度值:
在上述公式中,一个位置的灰度值仅仅依赖于相同位置的 RGB 值,显然不同位置之间的灰度化过程是彼此独立的,因而可以进行并行化。
2.2 CUDA C program structure CUDA C 程序结构
CUDA C 在 ANSI C 语法的基础上,通过添加新的语法和库函数使得程序员能够针对包含有 CPU 和 GPU 的异构计算系统进行编程。
CUDA C 程序的结构体现出主机 host(CPU)和设备 device(GPU)是在一个计算机上共存的。一个 CUDA C 源文件可能混合有主机和设备代码,也可以认为一个纯 C 文件就是一个仅含有主机代码的 CUDA C 文件。
CUDA 程序的执行过程如下图所示,从主机代码开始,然后调用设备代码。核函数将会调用很多 threads 来执行,由一个 kernel 调用的所有线程的集合被称为 grid。当所有线程执行结束,程序执行又回到主机代码,直到结束或者调用另一个设备代码。

注意,上图是一个简化的模型,事实上在很多异构应用中,CPU 和 GPU 执行过程可能重叠。
在灰度化的例子中,一个像素的灰度化可能由一个线程负责,那么图片越大,完成这个任务的线程数也就越多。得益于优秀的硬件支持,开发人员可以认为线程的创建和调度只需要几个时钟周期。而在 CPU 线程中,这一过程需要几千个时钟周期。
2.3 A vector addition kernel 向量加法核函数
向量加法在并行编程中的地位就像 Hello World 在顺序编程中一样。在顺序编程中,通过一个循环来实现向量加法。
向量加法由三部分构成,将数据从 host 搬运到 device,计算,再将数据从 device 搬运到 host。理论上来说,如果将搬运任务交给设备代码完成,那么对于设备来说,这个计算过程就是全透明的。但实际上,这部分任务由主机代码负责。
2.4 Device global memory and data transfer 设备全局内存和数据搬运
在 device 中,其一般都是带有自己的 RAM,被称为全局内存。前面提到,在 device 计算前后,数据要从 host mem 搬运到 gloabl mem,这一过程由运行在 host 上的 CUDA 运行时提供的 API 来完成。
有两个 API 用于申请和释放内存。cudaMalloc 用于申请内存,参数为一个指针的地址和内存大小(单位:字节),分配好的内存首地址将被写入传入的指针。cudaFree 用于释放内存。在主机代码中不得解引用 device mem,这会导致异常或者其它运行时错误。
内存分配结束后,就可以将数据从 host mem 拷贝到 global mem。使用的是 cudaMemcpy ( void* dst, const void* src, size_t count, cudaMemcpyKind kind ) 这个 API,包括四个参数:目的地址、源地址、字节数、类型。类型字段用于指定拷贝的方向,有四种方向 host/device to host/device。
2.5 Kernel functions and threading 核函数和线程
核函数指的是 GPU 线程并行执行的代码,这是一种典型的 SPMD 范式。当主机端调用一个核函数,所有的线程被组织为两级结构:一个核函数由一个 grid 运行,一个 grid 含有多个 blocks,一个 block 内有多个 threads。每个 block 内 threads 的数量都是相同的,且最多为 1024 个。
每一个线程内都有一个有运行时负责维护的内建变量 blockDim,其包括三个数据域 x,y,z,用于记录一个 block 内线程的数量。三个数据域说明其支持将一个 block 中的所有 thread 按照最多三维的形式组织,以便与待处理的数据有更好的对应关系。出于性能考虑,建议每个维度的数量均为 32 的整数倍。
还有两个内建变量 threadIdx 和 blockIdx 分别 thread 在 block 内部的索引和 block 在 gird 内部的索引。使用公式 int i = blockDim * block + blockIdx 可以计算每个 thread 的全局索引,如过让每个 thread 负责向量加法中一个元素的计算,那么 n 个 thread 就可以计算长度不超过 n 的向量加法,对应的核函数实现为:
|
|
注意到这里使用了限定修饰符 __global__ 用于生命此函数既可以 host 调用,也可以被 device 调用。CUDA C 引入了还引入了两个关键字 __host__ 和 __device__,前者是默认行为,表示该函数在 host 上运行,只能被 host 调用;后者则表示该函数在 device 上运行,只能被 device func 或者 kernel 调用,device func 本身不会新建任何线程。
此外,可以同时使用 __host__ 和 __device__ 修饰一个函数,这意味着编译器将分别为 host 和 device 生成不同的版本
2.6 Calling Kernel functions 调用核函数
完整的调用过程如下所示:
|
|
捅过 <<< 和 >>> 指定在调用 kernel 时 block 和每个 block 中 thread 的数量,使用向上取整确保向量加法没有遗漏。
在执行过程中,block 的调度对程序员是透明的,其取决于 GPU 的规模和运算速度。block 之间是独立的。
2.7 Compilation 编译
CUDA C 的编译运行过程如下所示,首先由 NVCC 将主机代码和设备代码进行分离,主机代码交由主机的 C 编译器进行编译链接,设备代码将被编译为 PTX 的虚拟二进制格式,然后再由设备的 JIT 进行二次编译运行。

Chapter 3: Multidimensional girds and data 多维网格和数据
3.1 Multidimensional grid organization 多维网格组织
前面提到,grid 和 block 都能以多维的形式进行组织。这个数量也并非无上限,gridDim.x 的最大值是 2^31-1,gridDim.y/z 的最大值均是 2^16-1。而对于 block 来说,其内部线程的数量约束为线程的数量不超过 1024。
可以使用 dim3 类型定义描述 gird 和 block 形状的变量,按照 x、y、z 的顺序:
|
|
而我们在使用下标来索引描述一个 block 或者 thread 的过程,则是按照 z、y、x 的顺序,例如 block(1, 0) 表示 x 为 0、y 为 1 的 block,这种顺序便于描述线程和数据之间的映射关系。
3.2 Mapping threads to multidimensional data 将线程映射到多维数据
线程的组织形式取决于数据的内在结构。例如,对于图片数据来说,按照二维来组织线程有利于处理像素。
例如,如果要对每个 62*76 的图片进行像素处理,可以使用 16×16 的线程组织为一个 block,4×5 的 block 组织为一个 grid。最终按照如下所示的形式对原图片(阴影部分)进行覆盖。

在 CUDA C 中,数据按照行优先的顺序在内存中存储。
Image blur: a more complex kernel 一个更复杂的核函数:图片模糊
在本小节中将实现一个更为复杂的核函数:图片模糊,图片模糊是对每个像素包括它自己的周围区域像素取加权均值得到,本节中权重均为 1,在实际应用中往往根据到中心点的远近取不同的权重值。
|
|
3.4 Matrix multiplication 矩阵乘法
矩乘是线性代数算法中基础算法之一,矩乘定义不再赘述。类似于之前一个 thread 负责一个位置计算的思想,可以写出最朴素版本的矩阵核函数:
|
|
Chapter 4: Compute architecture and scheduling 计算架构和调度
本章节从现代 GPU 架构讲起,主要介绍 GPU 在执行过程中线程的调度机制,以及制约占用率的一些因素。
4.1 Architecture of a modern GPU 现代 GPU 架构
下图展示了在程序员视角中的 GPU 架构。其由一系列流式多处理器 streaming multiprocessors SM 组成,每个 SM 由多个流处理器或者称 CUDA 核心组成。在一个 SM 内部,其共享控制单元和 on-chip mem。
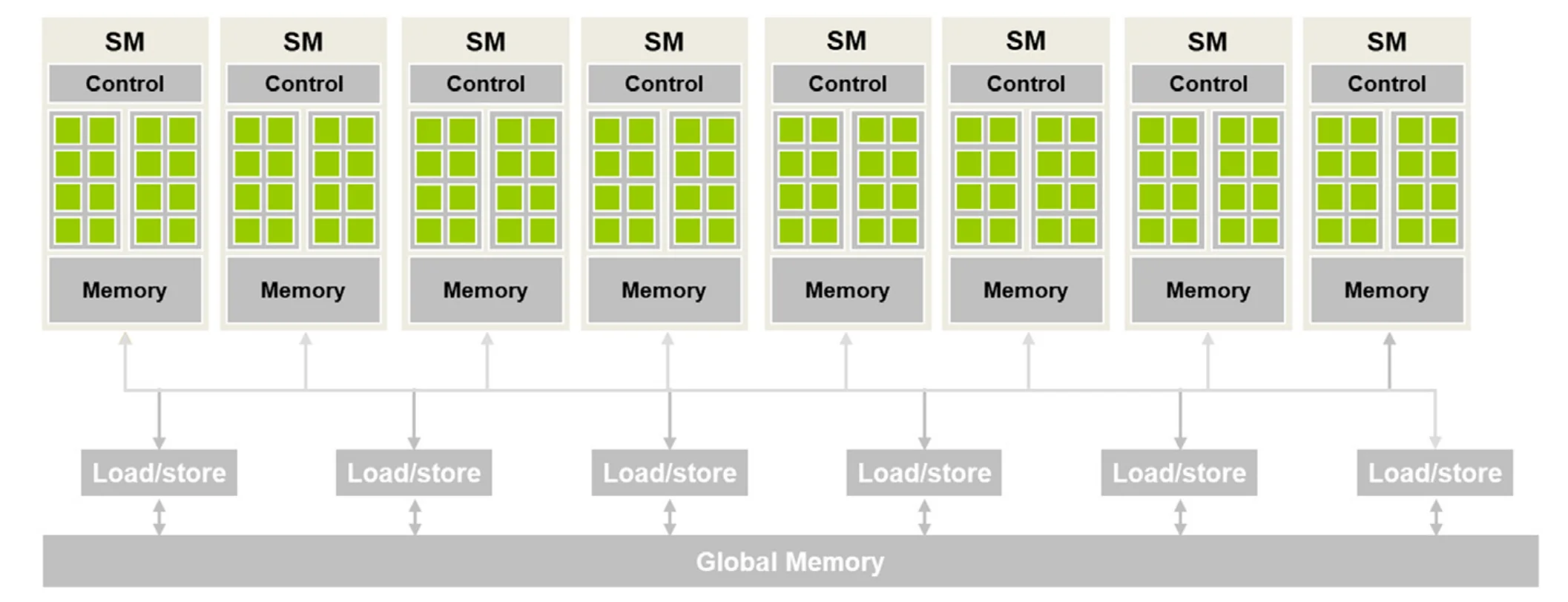
4.2 Block scheduling Block 调度
当一个核函数被调用时,CUDA 运行时会启动一系列线程,这些线程以 block 为单位分配给 SM,一个 SM 可以被分配多个 block。当然,由于硬件资源的限制,一个 SM 分配的 block 数量是有限的。由于 SM 和 SM 分配的 block 的数量有限,同时执行的 thread 数量也是有限的,这就以为着注定有一些线程不是并行执行的。
4.3 Synchronization and transparent scalability 同步和透明可扩展性
CUDA 允许线程之间通过 __syncthreads() 函数进行彼此协调(同步)。当一个线程调用该函数,其会在此处阻塞,直至所有线程均执行到这里。这种同步技术被称为屏障同步 barrier synchronization。
在 CUDA 中,如果使用 __syncthreads 进行线程同步,一个 block 内的所有线程都必须执行该同步。如果该语句在条件分支中,则该 block 内的线程要么都经过这个分支,要么都不经过这个分支,不能出现“部分同步”的现象,这是未定义行为。
同一个 block 内的 thread 抵达屏障阻塞的时间应当大致相同,CUDA 运行时会确保同一个 block 内的 thread 同时开始执行。
上述屏障同步机制可以看出 CUDA 在设计时的折中:通过禁止跨 block 的线程同步,这使得 CUDA 能够以任意顺序调度这些 block。进一步地,这种调度的任意性为透明可扩展性奠定了基础:对于 SM 比较少的设备来说,其可以每次执行少量的 block,对于 SM 很多的设备来说,其也许能够一下子调度所有的 block 进行执行。这种在不同的设备上执行同一份代码的能力,被称为透明可扩展性。
4.4 Warps and SIMD hardware 线程束和 SIMD 硬件
SM 内部线程的调度策略取决于具体的硬件实现,在目前大部分的设备中,一个 block 内的线程会按照 32 为一个单位组成线程束,SM 内部的调度以线程束为单位进行。如果剩余线程不满 32 个,则会填补一些非激活线程凑满一个线程束。
对于多维 block,首先将内部的线程按照一维线性排列,然后划分线程束。
SM 内的线程束遵循 SIMD 模式,即每次取一条执行,由线程束内的所有线程一起执行。这些线程束内的线程共享同一套控制单元,具有相同的执行进度,这一模型被称为 SIMT 单指令多线程模型。
4.5 Control divergence 控制流分歧
如果线程束内的线程共享同一个控制流,那么按序执行即可;如果这些线程进入不同的控制分支时,那么这些线程束会依次进入所有必要的分支,在每个分支中对应的线程会被激活,其它线程则保持静止。
一个线程束内的线程具有不同的控制流路径,这一现象被称为控制流分歧。通过在不同的分支中激活不同的线程,CUDA 实现了线程束内控制流的完整语义,但其代价就是要依次通过所有必要的控制流。
在帕斯卡及其以前的架构中,这些分歧的控制流一定是依次通过的;但是在伏特极其以后的架构中,分歧控制流可能能够并行执行,这一特性被称为独立线程调度。
除了单纯的 if 语句,任何具有控制流的语句都可能导致控制流分歧,例如下面这段 for 循环的代码:
|
|
对于循环语句,可以根据其退出条件判断是否存在控制流分歧。如果条件中涉及到了 threadIdx,就有可能存在分歧。
使用控制语句的一个主要场景是用于处理数据的边界情况。具体来说,经常需要将数据划分给线程,但是数据量不一定是线程数的整数倍,因此需要控制语句判断边界,防止越界存取。
随着数据量的增大,控制流分歧带来的代价反而会降低。对于 100 个数据,有 1/4 的线程束内部存在分歧;对于 1000 个数据,只有 1/32 的线程束内部存在分歧。
4.6 Wrap scheduling and latency tolerance 线程束调度和延迟容忍
一个 SM 被分配到的线程数往往比核心更多,这意味只有一部分线程能够立刻执行。在早期 GPU 设计中,一个 SM 每次只能执行一个线程束的一条指令;而在最近的 GPU 设计中,每个 SM 能够执行来自不同线程束的指令。但无论如何,每个 SM 每次也只能执行一部分而非所有的线程束。
那为什么要分配超过其执行能力数量的线程束给单个 SM 呢?答案在于 GPU 需要通过这种方式来克服一些延迟比较大的操作带来的开销,例如访问全局内存的操作。
当一个线程束需要长时间等待访存操作完成时,线程束将被阻塞执行,同时调度器将调度就绪的线程执行。这一技术被称为延迟容忍或者延迟隐藏。
值得一提的是,在 CUDA 中的线程调度几乎不存在开销,这被称为零开销线程调度。CUDA 延迟容忍的特性使得其不需要像 CPU 一样在计算单元附近放置大量 cache,相反,可以放置大量浮点计算单元。
要实现高效的延迟容忍,一个 SM 就需要被分配大量线程束,使得其随时都能调度就绪线程束。在 A100 GPU 中,一个有 64 核的 SM 甚至最多能分配 2048 个线程。
4.7 Resource partitioning and occupancy 资源分配与占用
SM 实际分配的线程数与最大可分配数量的比值被称为占用率,占用率越高,SM 潜在执行效率也就越高。制约占用率最大化的一个因素是资源分配。
执行资源包括寄存器、共享内存、线程块槽位和线程槽位。这些资源被动态分配给线程以支持其执行。举个栗子,A100 最大支持每个 SM 32 blocks、每个 SM 64 个线程束、每个 block 1024 个线程。如果一个核函数按照每个 block 1024 个线程进行启动,那么每个 block 中有 32 个线程束,受制于第二个线程束条件,每个 SM 只能被分配 2 个 block。
资源的动态分配使得 SM 既可以执行少数具有大量 thread 的 block,也可以执行大量具有少数 thread 的 block。但这也可能导致低占用率。例如,在前面的栗子中,如果每个 block 只有一个线程束即 32 个线程,受制于 block 数量约束,这个 SM 最多只能分配 32 个线程束,占用率为 50%。又或者,如果每个 Block 的线程数不能被 SM 最大线程数整除,例如一个 Block 有 768 个线程即 24 个线程束,那么这个 SM 最多只能分配 48 个线程束,占用率为 75%。
寄存器同样是有限的资源,具体将在下一章中讨论。
4.8 Querying device properties 查询设备属性
怎么在运行时查询设备参数呢?每个 SM 资源的数量由计算能力 compute capability 定义,CUDA C 提供了 cudaGetDevicePropertiesAPI 用于获取设备的具体属性,其将写入一个 cudaDeviceProp 类型的返回值,该类型记录了 GPU 的详细信息。重点介绍如下字段:
maxThreadsPerBlock:每个 block 最多线程数multiProcessorCount:设备中 SM 的数量clockRate:时钟周期,与上一字段一起指示了该设备的吞吐量maxThreadsDim:每个 block 中线程各维度上限maxGridSize:grid 中 block 各维度上限regsPerBlock:一个 block 中寄存器上限,这个字段含义实际上指的是一个 SM 中可用寄存器数量,而非占用率 100% 时一个 block 中可数量的数量warpSize:线程束中线程数量
Chapter 5: Memory architecture and data locality 内存架构和数据索引
本章节系统介绍了 CUDA 中的内存架构,阐释了访存效率对于计算效率的影响,使用分块技术对矩乘进行改进,实现了 16x 的性能提升。
5.1 Importance of memory access efficiency 访存效率的重要性
以 3.4 Matrix multiplication 矩阵乘法 中给出的矩阵乘法为例,每个线程负责结果中一个元素的计算,即计算两个向量的内积。
|
|
如上所示,在计算内积的循环中,每次都要访问两次全局内存,以及 2 次浮点计算。这里引入一个指标“计算密度” computational intensity,计算公式为浮点操作数 FLOP 比上全局访存字节数,在上述代码中,计算密度为 2FLOP/8B = 0.25FLOP/B。
计算密度这一指标能够指示该 CUDA 程序是否充分利用了核心的计算能力。例如,在 A100 张中,全局访存带宽为 1555GB/s,将其与计算密度相乘,可以得到该程序所需的浮点计算能力为 389GFLOPS,远低于 A100 实际具有的浮点计算能力 19500GFLOPS,遑论 A100 中还具有专门的 tensor core,具有 156000GFLOPS 的浮点算力。
这类被内存带宽拖累的程序被称为内存瓶颈程序。根据 A100 的全局带宽和浮点计算能力,我们可以计算出至少需要 19500/1555=12.5FLOP/B 的计算密度才能充分发挥其计算性能。
5.2 CUDA memory types CUDA 内存类型
CUDA 设备提供了多种内存类型以提高计算密度,如下所示。

最底层的为全局和常量内存,host 可以对其读写,device 可以对全局内存读写,可以对常量内存以低延迟和高带宽进行读,而不可写。
还有一部分是局部内存,其实际上是全局内存的一部分,与全局内存具有类似的延迟和带宽。每个线程会在全局内存中分配一段仅其自己可读写的内存作为局部内存,用于存放寄存器放不下的变量,例如静态数组、溢出的寄存器以及线程的函数调用栈。
寄存器和共享内存是片上内存,其中的变量能够并行地以非常高的速率被访问。寄存器仅对该线程自己可见,用于保存线程经常使用到的一些仅自己可见的变量,共享内存则由一个 Block 内的所有变量共享。
通过使用不同的内存类型,程序员可以控制不同变量的访问速度和可见性。
除了本身的延迟和带宽,访问寄存器更快还有一个原因是指令数量。将两个寄存器中的浮点数相加只需要一条浮点数加法指令,而如果两个不在寄存器中的浮点数加起来则需要额外指令将数据加载到寄存器、将结果搬运回内存。执行这些额外指令本身也会消耗更长的时间。
尽管寄存器和共享内存都是片上内存,但共享内存是内存体系的一部分,其中数据也需要读取到寄存器中再操作,因此相比寄存器其具有更高的延迟和更低的吞吐量。术语 scratchpad memory 指的就是这一部分板上内存。
声明的不同类型的变量其保存的位置、作用域和声明周期各不相同,具体对应关系如下表所示:
| 变量声明 | 内存 | 作用域 | 生命周期 |
|---|---|---|---|
| 非数组的自动变量 | 寄存器 | thread | 网格 |
| 自动数组变量 | 本地 | thread | 网格 |
__device__ __shared__ int SharedVar; |
共享 | block | 网格 |
__device__ int GlobalVar; |
全局 | grid | 应用程序 |
__device__ __constant__ int ConstVar; |
常量 | grid | 应用程序 |
5.3 Tiling for reduced memory traffic 通过分块减少访存
将数据划分为在共享内存中放得下的小块可以减少对全局内存的访问,数据分块的前提是每一块都可以独立地进行计算,不是所有的数据结构、也不是所有的核函数都可以进行分块处理。

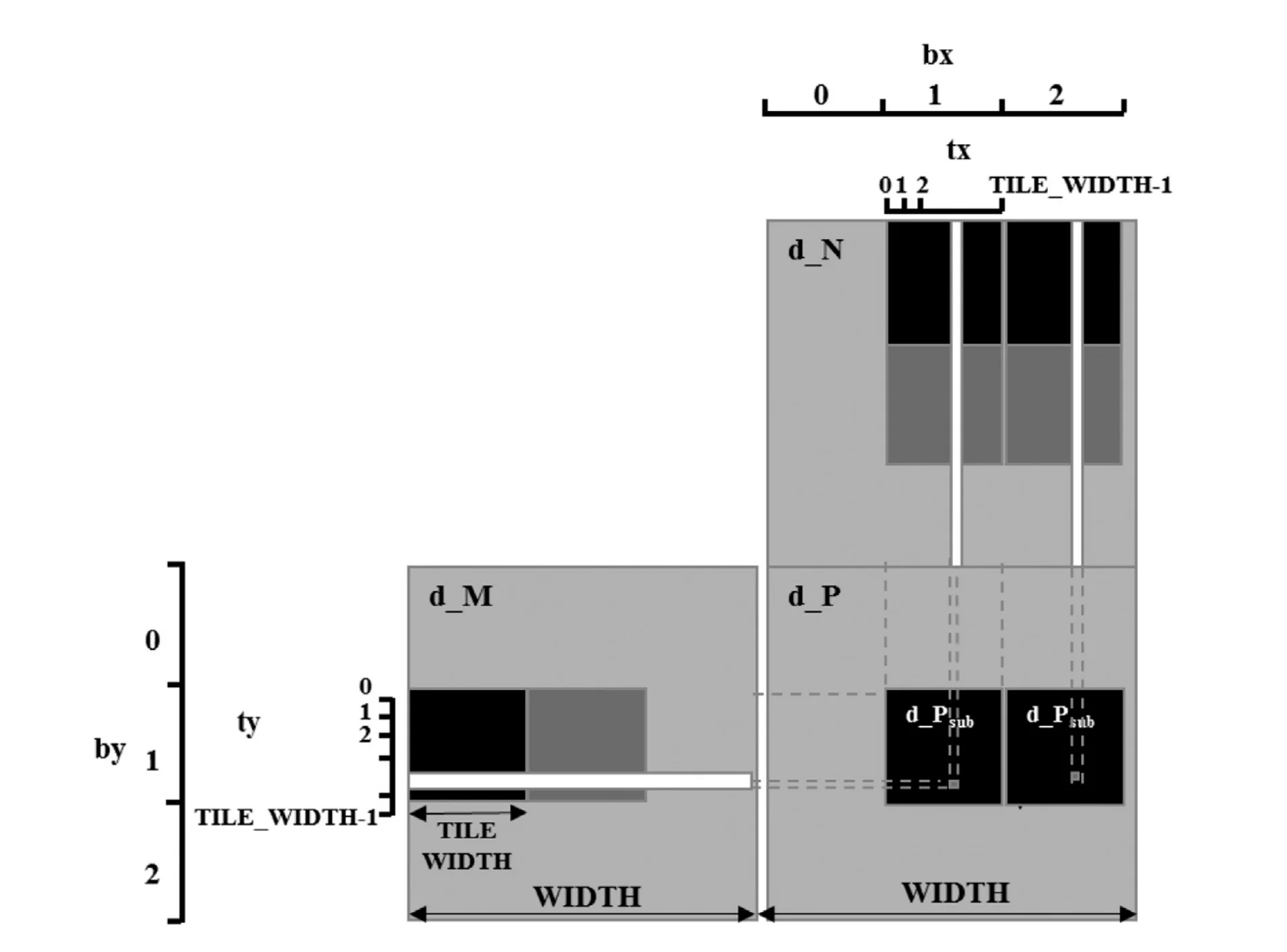
如上图所示,正在之前实现的矩阵乘法中,每个线程独立计算一个元素,第一个 block 由四个线程组成,这些线程之间有重复读取全局内存的过程,例如 P00 和 P01 均读取了 M 的第一行。可以通过将这些元素读入共享内存来实现对全局内存的减半访问。
在矩乘中,实际减少的访存次数取决于 block 的 size,具体来说,如果 block 中的线程以 n×n 的规格组织,则能够将访存次数减少到 1/n。
需要注意的是,共享内存的大小是有限的,如果一个 block 中的线程数过多或者矩乘中的维度过大,共享内存可能存不下分块后需要用到的数据,此时可以将其划分为更小的块以便读入共享内存中。
例如,按照 2×2 对 M 和 N 进行分块,4×4 的矩乘将由两阶段完成。对于 block00 来说,第一阶段将 M[0:2, 0:2] 和 N[0:2, 0:2] 读入共享内存计算矩乘;第二阶段将 M[0:2 2:4] 和 N[2:4, 0:2] 读入共享内存,计算矩乘并累加到前面的结果中。各线程完成的任务如下表所示:

5.4 A tiled matrix multiplication kernel 分块矩乘核函数
分块矩乘核函数如下:
|
|
与之前的分析类似,首先声明两个共享内存用于存放当前阶段计算需要用到的数据。在阶段的循环中,首先 co-fetch 数据到共享结存中然后进行矩乘计算。这里使用了两次同步,第一次是防止数据还没有加载完就进行读取,第二次是防止计算还没完成就写入下一阶段的数据。
16-26 行演示一种被称为 strip-mining 的技术,即将原始很长的循环划分为多个阶段进行,每个阶段内部有一个嵌套循环负责执行原循环中连续的一小部分。
通过分块,我们将矩乘核函数的计算密度从 0.25 OP/B 提升到了 4 OP/B,这是 16 倍的提升。当然,离 A100 12.5 OP/B 还有很远的距离。更多的优化方法将在后文中继续讨论。
5.5 Boundary check 边界检查
这节私以为没有单独拎出来的必要,核心内容就是在加载数据和计算时都要进行边界检查,不要越界。此节跳过。
5.6 Impact of memory usage on occupancy 内存使用对使用率的影响
正如第四章所提到的,寄存器和共享内存的过度使用将成为制约每个 SM 中分配到的线程数的负面因素。例如,在 A100 中,每个 SM 共享内存大小为 164KB,按照按照最大线程数 2048 计算,一个 block 中平均每个线程使用的共享内存大小不能超过 164KB/2048 = 82B。而在我们之前的矩乘中,每个线程平均加载了 2 个浮点数,即 8B,小于 82B。这说明在之前的核函数中,内存使用不会成为瓶颈。
可以针对不同的硬件平台,使用不同大小的共享内存。这涉及到了 CUDA 中动态分配共享内存技术,使用关键字 extern __shared__ 来声明一个动态共享内存:
|
|
该动态数组只有一个,如果由多个变量共享,需要由程序员控制不同变量之间的边界。
在调用核函数时,使用第三个参数动态传入共享内存的大小。还可以在核函数的参数中增加相应的字段用于表示共享内存中不同变量的长度。
Chapter 06: Performance considerations 性能考量
本章节介绍了几种性能优化技术:内存合并访问、隐藏内存延迟和线程粗化,并对本书第一部分所提及的性能优化技术进行小结。
6.1 Memory coalescing 内存合并访问
在上一章中介绍了共享内存以缓解全局内存带宽瓶颈,在本章中将介绍内存合并访问技术以更高效地在全局内存和共享内存之间搬运数据。
DRAM 的物理结构决定了其支持突发访存,即当访问某个位置的元素时,其周围连续的元素也会被一起读取。
为了充分利用突发访存的特性,CUDA 会自动将线程束中的多个线程连续的访存指令转换为突发访存指令,即如果线程束中 0-31 号线程的同一个访存指令访问的目标是全局内存中连续的 32 个位置,则该访存指令将通过突发访存来实现。
例如,在如下的矩乘实现中,每个线程从第二个矩阵中取一列进行计算。在主循环中,每个线程从其对应列中取一个元素,从线程束的视角来看,同一个线程束内部的线程每轮循环都在对连续的位置进行访存。

与之相反的是,如果第二个矩阵在内存中按照列优先排布,那么每个线程内部访存是连续的,但是线程束内线程之间访存是非连续的,这使得内存合并访问技术不可用。

针对上述用情况,有几种解决方案:修改线程与数据之间的映射方式、修改数据的排布方式、使用共享内存通过内存合并访问加载数据。第三种技术被称为数据重排 corner turning.
具体来说,数据重排就是通过内存合并的方式将在计算过程中不能合并访问的数据加载到共享内存中,共享内存使用 SRAM,因此无论按照行/列优先访问都具有相同的速度。
6.2 Hiding memory latency 隐藏内存延迟
仅使用突发访存这一并行访存技术并不能满足 CPU/GPU 对于访存带宽的需求,还需要使用多通道技术。
每个处理器上都有具备独立内存控制器的多个通道,每个通道通过独立总线连接至不同的内存上,从而实现并行内存读取。
总线上数据的传输带宽取决于时钟频率和字长,现代 DDR 总线在每个上升和下降沿都可以传输一次数据,因此 64-bit 且频率为 1 Ghz 的总线带宽为 16 GB/s。
单个存储片除了突发访存时间外还有很大一部分比例的时间(远大于访存时间)用于准备数据,因此单个通道可能会连接到多个存储片,通过流水线来最大化利用总线带宽。
本节剩余内容似乎在讲交叉存储器,看计组英文版有点头疼,笔记跳过。
6.3 Thread coarsening 线程粗化
在前面的案例中,我们大多按照最小粒度为线程划分任务,例如每个线程负责一个元素的计算。但由于并行化开销的存在,并非线程越多越好。此外,由于硬件限制,部分线程可能需要等待其它线程完成后才能被调度,这种情况下,并行开销反而是无意义的,可以使用线程粗化技术,给每个线程分配多个任务单元。
如下图所示,在矩乘中,每个线程可以负责计算两个连续的子块,其只需要读取一次 M 的同一行,减少了访存次数。
线程粗化可能能够显著提升性能,仅当并行化存在开销的情况,例如重复加载数据、重复计算、同步开销等,否则可能导致粗化不能改进性能。第二个缺点是粗化可能导致硬件利用率下降,硬件利用率依赖于高度并行化,而线程粗化会降低这一点。第三个缺点是粗化可能导致占用率下降,具体来说,粗化后的内核程序可能需要更多的寄存器和共享内存资源,进而导致占用率下降。
6.4 A checklist of optimizations 优化清单
到本章结束,本书的第一部分就已介绍完毕。在第一部分中,介绍了几种优化策略,总结如下:
| 优化项 | 对计算核心的好处 | 对内存的好处 | 策略 |
|---|---|---|---|
| 最大化占用率 | 更多工作以隐藏流水线延迟 | 更多并行内存访问以隐藏 DRAM 延迟 | 调整 SM 资源的使用,如每个块的线程数、每个块的共享内存和每个线程的寄存器数 |
| 启用合并的全局内存访问 | 更少的流水线停顿,等待全局内存访问 | 更少的全局内存流量和更好的突发/缓存线利用 | 以合并的方式在全局内存和共享内存之间传输,并在共享内存中执行非合并访问(例如,角落转向) |
| 最小化控制分歧 | 高 SIMD 效率(SIMD 执行期间空闲核心更少) | — | 重新安排线程到工作和/或数据的映射 |
| 分块重用数据 | 更少的流水线停顿,等待全局内存访问 | 更少的全局内存流量 | 将在块内重用的数据放在共享内存或寄存器中,使其仅在全局内存和 SM 之间传输一次 |
| 私有化(稍后介绍) | 更少的流水线停顿,等待原子更新 | 更少的原子更新争用和序列化 | 将部分更新应用于数据的私有副本,然后在完成时更新通用副本 |
| 线程粗化 | 更少的冗余工作、分歧或同步 | 更少的冗余全局内存流量 | 为每个线程分配多个并行单元,以减少不必要的并行性代价 |
在本书的后面两个部分,将应用表格中的技术来优化并行程序,通过实践来理解和应用。
6.5 Knowing your computation’s bottleneck 了解性能瓶颈
要对计算程序进行优化,必须针对其瓶颈进行,否则可能收效甚微。遗憾的是,本书似乎不会涉及太多有关性能瓶颈识别的内容,作者推荐了 NVIDIA 官方的工具指南:Profiler。