资源存档
Chapter 1: Introduction 简介
应用程序需求的算力和 CPU 能够提供的算力一直是一对相互促进的矛盾。上世纪八九十年代,通过不断提高单核频率和每个时钟周期执行的活动数让算力达到了 TFLOPS 的级别。然而,到了 21 实际,由于功率和散热限制,难以通过提升频率进一步提高算力。这种情况下,多核 CPU 就应运而生了。多核 CPU 可以同时执行多个指令序列,因此应用程序也必须将任务分为多个部分以便在多个核心上同时执行。如果不针对多核进行优化,那程序很难享受到多核带来的算力提升。
这类能够享受到多核性能提升的程序被称为并行程序 parallel programs。
1.1 Heterogeneous parallel computing 异构并行计算
2003 年,在处理的进化道路上出现了一个分岔口。
一种以多核 multicore 见长,每个核心都是完整的一个单核 CPU,这就是现代的多核 CPU。例如 Intel 发布的最新处理器中,往往具有十几个核心,每个核心都具有超线程能力,并且完整实现了 x86 指令集。
另一种以多线程 many-thread 见长,能够同时执行非常非常多的线程,往往具有极强的浮点计算能力,这就是现代 GPU。例如 NVDIA 发布的 A100 GPU 中,其双精度浮点算力达到 9.7 TFLOPS,同期的Intel 24核处理器只有 0.66 TFLOPS。
如下图所示,这一差异源自二者设计理念的差别。CPU为了支持顺序执行指令序列,其在设计时最小化了算数运算的延迟,并且提供了很大的末级缓存以便快速存取大量数据,还应用了许多复杂分支预测和执行控制逻辑技术来减少分支指令带来的延迟。上述技术消耗了大量的芯片面积和功耗,这种设计理念被称为面向延迟的设计。与之相反的是GPU的设计理念,即面向吞吐量的设计。GPU的快速发展起初是由电子游戏推动的,每个游戏帧的渲染都需要计算大量浮点数,因此GPU最大化了浮点数的计算单元。
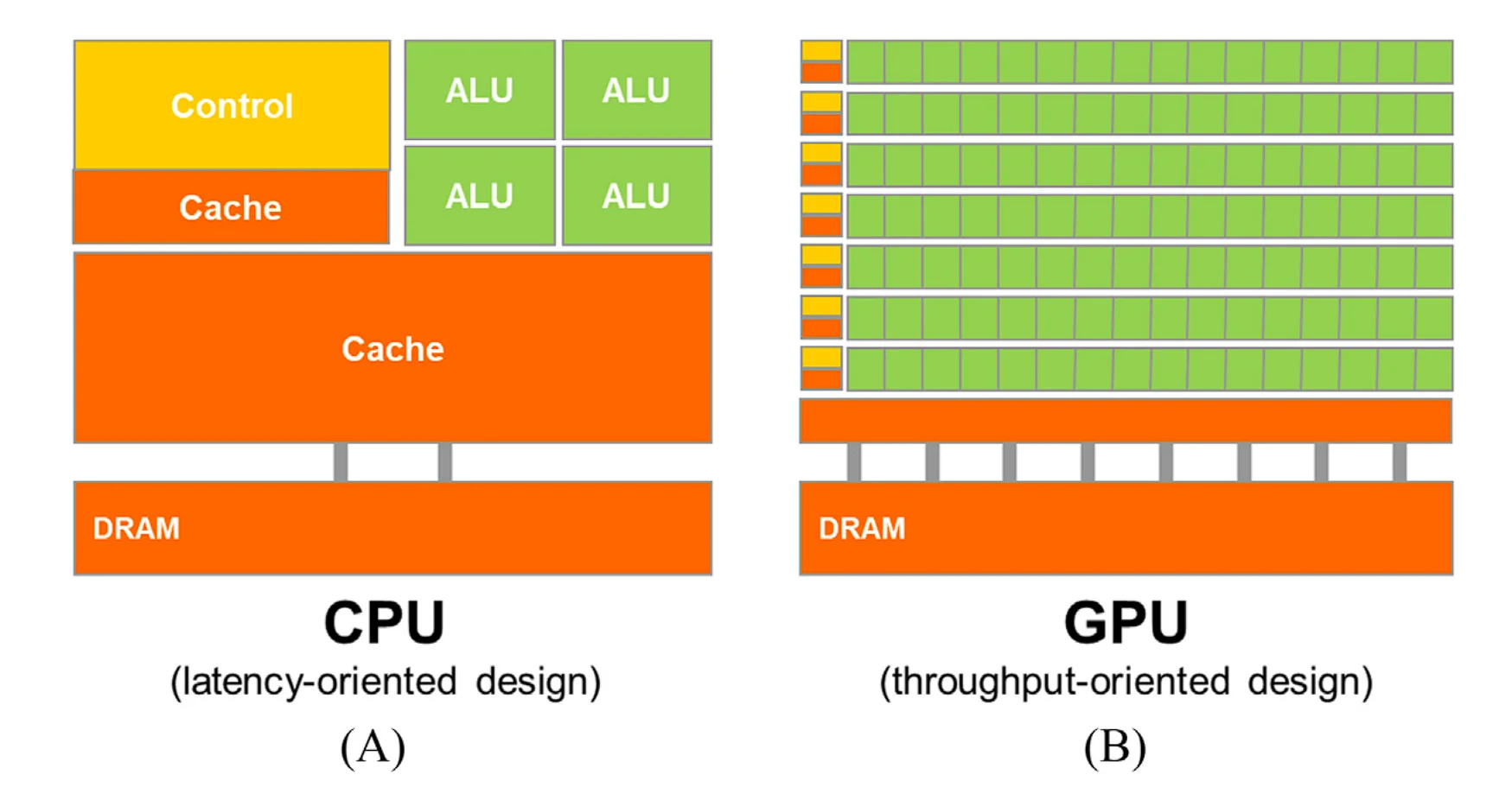
对于GPU而言,同时进行大量的浮点计算是重要的,但是同时大量访存这一点也很重要。GPU要能够在内存中快速移动大量数据。GPU通常可以接受宽松内存模型1。
丧心病狂的芯片研发人员为了榨取更多的性能,在PSO模型基础上,更进一步的放宽了内存一致性模型,不仅允许store-load,store-store乱序。还进一步允许load-load,load-store乱序, 只要是地址无关的指令,在读写访问的时候都可以打乱所有load/store的顺序,这就是宽松内存模型(RMO)。
然而,作为通用处理器的CPU为了满足各类应用程序、老旧OS、IO设备等的要求,在内存上就不能这么激进了。通常,GPU的内存带宽能够达到CPU的10倍。
通常来说,提高减少延迟比提高吞吐量要困难,通过让计算单元翻倍就能让吞吐量翻倍。GPU为了提高吞吐量,增大了算术元件和内存的延迟。
GPU应用程序需要有大量的并行线程,当在等待内存数据时,GPU的其它线程可以用于查找接下来要完成的任务。这类设计模式被称为面向吞吐量设计。
GPU执行吞吐量很高,然而其并不擅长CPU所擅长的领域,因此,在英伟达2007年引入的CUDA模型中,其支持CPU-GPU联合执行。
在CUDA出现之前,与GPU交互的接口为OpenGL和Direct 3D,它们都是用于绘制像素的API,即便是用GPU来计算,其底层仍是这些与像素相关的接口。这种技术被称为GPGPU,general purpose GPU。
在CUDA推出以后,GPU计算不再需要调用图形接口,而是由专用的通用计算接口。
1.2 Why more speed or parallelism 为什么要并行化?
现在普通应用已经运行得足够快了,为什么还要并行化?事实上,在很多任务中,运行速度仍是瓶颈。得益于GPU的迅速发展,科学计算、视频、电子游戏、深度学习等也繁荣起来。
以上种种应用都有一个特点,就是有大量的数据需要处理。这种情况下,可以并行执行大数据处理任务,以显著提升执行效率。
1.3 Speeding up real applications 加速实际应用
如何评价并行化后的加速倍率?我们通过比较加速前后的运行时间即可,通过加速将运行时间从200秒减少到10秒,那我们就称加速倍率为20×。
一个应用程序的加速倍率,取决于该程序能够并行化的部分的比例。例如,如果一个程序有30%的部分可以实现100×加速,那么这个程序的执行时间最多只能降低29.7%,整体加速效果为1.42×。一个系统的加速效果严重受制于可加速的部分的比例,这一定律被称为阿姆达尔定律。
另一个制约加速倍率的因素是内存带宽,因此在并行技术中一个重要方面就是尽可能减少主机内存访存次数,改为访问GPU显存。
1.4 Challenges in parallel programming 并行编程中的挑战
编写并行程序可能很难,有些并行程序需要完成的任务可能有很多,甚至比原始版本跑得还慢。主要困难有以下几个方面。
- 编写并行算法的思维方式和惯用的顺序执行的算法思维方式完全不同。
- 并行算法很容易受到内存贷款瓶颈。
- 并行化的算法对于输入数据的特征更加敏感。
- 并行化的算法不同线程之间可能需要协作,而这些线程之前的同步也会带来额外开销。
1.5 Related parallel programming interfaces 相关并行编程接口
在过去几十年中,有不少并行编程语言和模型被提出。对于共享内存的多处理器系统,最常用的是OpenMP,对于可扩展集群计算,最常用的是Message Passing Interface (MPI)。
OpenMP由编译器和运行时两部分组成。程序员通过在代码中指定指令directives和编译指示pragmas,编译器可以生成并行代码,运行时负责通过管理线程和资源以支持并行运行。OpenMP通过提供自动编译和运行时支持使得程序员们不需要考虑并行编程的细节,也方便在不同的系统/架构中迁移
在MPI中,同一个簇内的计算节点不共享内存,所有的数据和信息通过消息传递机制进行,MPI适合超大规模的HPC集群(节点超过10万个)。由于不共享内存,对于输入输出的分割工作,大部分由编程人员来完成。与之相反,CUDA提供了共享内存。
2009年,工业界几个巨头,包括苹果、因特尔、AMD和英伟达一起开发了一个标准编程模型OpenCL。
1.6 Overarching goals 首要目标
最首要的目标是实现在大规模并行编程中的高性能编程。本书会涉及一些对硬件架构的直觉上的理解,一些计算思维,即以适合大规模并行处理器的执行方式来思考问题。
第二个目标是在并行编程中实现正确的功能和可靠性。CUDA提供了一系列工具来对代码的功能和性能瓶颈进行Debug。
第三个目标是实现对未来更高性能的硬件的可扩展性。这种可扩展性是通过规范化和本地化内存,以减少在更新数据结构中对关键资源的读写和冲突来实现的。
1.7 Organization of the book 本书的架构
略。
Chapter 2: Heterogeneous data parallel computing 异构数据并行计算
2.1 Data parallelism 数据并行化
数据彼此独立是数据并行化的基础,通过对计算任务的重新组织,可以将数据并行化,进而获得可观的加速效果。以将像素灰度化举个例子,通过如下公式来计算灰度值:
2.2 CUDA C program structure CUDA C 程序结构
CUDA C在ANSI C语法的基础上,通过添加新的语法和库函数使得程序员能够针对包含有CPU和GPU的异构计算系统进行编程。
CUDA C程序的结构体现出主机host(CPU)和设备device(GPU)是在一个计算机上共存的。一个CUDA C源文件可能混合有主机和设备代码,也可以认为一个纯C文件就是一个仅含有主机代码的CUDA C文件。
CUDA程序的执行过程如下图所示,从主机代码开始,然后调用设备代码。核函数将会调用很多threads来执行,由一个kernel调用的所有线程的集合被称为grid。当所有线程执行结束,程序执行又回到主机代码,直到结束或者调用另一个设备代码。

注意,上图是一个简化的模型,事实上在很多异构应用中,CPU和GPU执行过程可能重叠。
在灰度化的例子中,一个像素的灰度化可能由一个线程负责,那么图片越大,完成这个任务的线程数也就越多。得益于优秀的硬件支持,开发人员可以认为线程的创建和调度只需要几个时钟周期。而在CPU 线程中,这一过程需要几千个时钟周期。
2.3 A vector addition kernel 向量加法核函数
向量加法在并行编程中的地位就像Hello World 在顺序编程中一样。在顺序编程中,通过一个循环来实现向量加法。
向量加法由三部分构成,将数据从host搬运到device,计算,再将数据从device搬运到host。理论上来说,如果将搬运任务交给设备代码完成,那么对于设备来说,这个计算过程就是全透明的。但实际上,这部分任务由主机代码负责。
2.4 Device global memory and data transfer 设备全局内存和数据搬运
在device中,其一般都是带有自己的RAM,被称为全局内存。前面提到,在device计算前后,数据要从host mem 搬运到gloabl mem,这一过程由运行在host上的CUDA运行时提供的API来完成。
有两个API用于申请和释放内存。cudaMalloc用于申请内存,参数为一个指针的地址和内存大小(单位:字节),分配好的内存首地址将被写入传入的指针。cudaFree用于释放内存。在主机代码中不得解引用device mem,这会导致异常或者其它运行时错误。
内存分配结束后,就可以将数据从host mem拷贝到global mem。使用的是cudaMemcpy ( void* dst, const void* src, size_t count, cudaMemcpyKind kind )这个API,包括四个参数:目的地址、源地址、字节数、类型。类型字段用于指定拷贝的方向,有四种方向host/device to host/device。
2.5 核函数和线程
核函数指的是GPU线程并行执行的代码,这是一种典型的SPMD范式。当主机端调用一个核函数,所有的线程被组织为两级结构:一个核函数由一个grid运行,一个grid含有多个blocks,一个block内有多个threads。每个block内threads的数量都是相同的,且最多为1024个。
每一个线程内都有一个有运行时负责维护的内建变量blockDim,其包括三个数据域x,y,z,用于记录一个block内线程的数量。三个数据域说明其支持将一个block中的所有thread按照最多三维的形式组织,以便与待处理的数据有更好的对应关系。出于性能考虑,建议每个维度的数量均为32的整数倍。
还有两个内建变量threadIdx和blockIdx分别thread在block内部的索引和block在gird内部的索引。使用公式int i = blockDim * block + blockIdx可以计算每个thread的全局索引,如过让每个thread负责向量加法中一个元素的计算,那么n个thread就可以计算长度不超过n的向量加法,对应的核函数实现为:
|
|
注意到这里使用了限定修饰符__global__用于生命此函数既可以host调用,也可以被device调用。CUDA C引入了还引入了两个关键字__host__和__device__,前者是默认行为,表示该函数在host上运行,只能被host调用;后者则表示该函数在device上运行,只能被device func或者kernel调用,device func本身不会新建任何线程。
此外,可以同时使用__host__和__device__修饰一个函数,这意味着编译器将分别为host和device生成不同的版本